

Als Datenschutzbeauftragte (DSB) müssen wir die Einführung neuer Technologien zur Verarbeitung personenbezogener Daten von Anfang an begleiten. Dies gilt besonders für KI-Systeme, die häufig große Mengen personenbezogener Daten verarbeiten, darunter oft auch sensible Daten gemäß Art 9 Abs. 1 DSGVO.
In diesem ersten Teil einer zweiteiligen Serie stelle ich konkrete Konzepte und Best Practices für datenschutzfreundliche KI vor. Auch wenn sich der Artikel mit sehr komplexen KI-Systemen beschäftigt, die typischerweise in großen Organisationen mit entsprechenden Teams und Ressourcen entwickelt werden, ist er auch für kleinere Organisationen wertvoll. Denn die hier beschriebenen Grundsätze und Anforderungen gelten – in angepasstem Umfang – auch beim Einsatz vorgefertigter KI-Lösungen oder vortrainierter Modelle. Der Artikel bietet eine umfassende Orientierung für ein Datenschutzkonzept beim Einsatz von KI-Systemen, das je nach konkretem Anwendungsfall und verfügbaren Ressourcen skaliert werden kann.
Meine Empfehlungen basieren auf zwei Säulen: zum einen auf meiner langjährigen Erfahrung bei der Einführung neuer Prozesse und Technologien, zum anderen auf meiner aktuellen Weiterbildung im Bereich KI. Diese Lernreise möchte ich mit Euch teilen.
1. Privacy by Design in der KI-Entwicklung
Grundprinzipien
Datenschutz von Anfang an in den Entwicklungsprozess integrieren
Der Grundsatz “Privacy by Design” bedeutet weit mehr als nur eine nachträgliche Prüfung von Datenschutzaspekten. Bei der Entwicklung von KI-Systemen muss der Datenschutz integraler Bestandteil des Entwicklungsprozesses sein, und zwar von der ersten Konzeptphase an.
In der Praxis beginnt dies mit einer Datenschutz-Folgenabschätzung (DSFA). Die DSFA hilft dabei, potenzielle Risiken frühzeitig zu erkennen und entsprechende Schutzmaßnahmen zu planen. Gleichzeitig muss ein Datenschutzkonzept (DSK) erstellt werden. Beide, die DSFA und das DSK bilden als lebendige Dokumente den gesamten Entwicklungsprozess ab und müssen kontinuierlich fortgeschrieben werden.
Die Integration des Datenschutzes in den Entwicklungsprozess erfordert auch klare organisatorische Strukturen. DSB sollten von Beginn an eingebunden sein und regelmäßig konsultiert werden. Datenschutzanforderungen müssen als fester Bestandteil in die technische Spezifikation einfließen und bei jedem Entwicklungsschritt berücksichtigt werden.
Nicht zu vergessen ist die Dokumentation aller datenschutzrelevanten Entscheidungen. Dies gebietet, ebenso wie die Zweckbindung und die Transparenz, Art. 5 DSGVO, hier der Absatz 2 (Rechenschaftspflicht).
Ein eigens für die Entwicklung entstehende Verzeichnis der Verarbeitungstätigkeiten (VVT) sollte parallel zur Entwicklung geführt werden, um keine wichtigen Aspekte zu übersehen. Hier ist zu empfehlen, das anfangs äußerst granular zu führen. Auch die technischen und organisatorischen Maßnahmen (TOM) müssen von Anfang an geplant und dokumentiert werden. Beide werden nach Überführung der KI-Entwicklung in den Arbeitsalltag in die Dokumentation (VVT und TOM) übernommen, dafür kann von der sehr granularen auf eine eher zusammenfassende Darstellung gewechselt werden. Diese Zusammenfassung ist möglich, wenn die detaillierte Dokumentation der Entwicklungsphase als Nachweis der Einhaltung der Rechenschaftspflicht archiviert wird.
Die Entwicklungsteams benötigen entsprechende Schulungen und Sensibilisierung für Datenschutzthemen. Es reicht nicht aus, Datenschutz als rein technische Anforderung zu behandeln – vielmehr muss eine datenschutzfreundliche Entwicklungskultur etabliert werden. Dies bedeutet auch, dass Datenschutzaspekte bei Code-Überprüfungen und -Besprechungen und in der Qualitätssicherung gleichberechtigt neben funktionalen Anforderungen stehen.
Regelmäßige Tests der implementierten Datenschutzfunktionen sind unerlässlich. Diese müssen sowohl die technische Funktionsfähigkeit als auch die tatsächliche Wirksamkeit der Schutzmaßnahmen überprüfen. Dabei sollten auch extreme Anwendungsfälle und potenzielle Missbrauchsszenarien getestet werden.
Ein oft übersehener Aspekt ist die Notwendigkeit, Schnittstellen für die Umsetzung von Betroffenenrechten von Anfang an einzuplanen. Das System sollte optimalerweise technisch in der Lage sein, Auskunftsanfragen zu beantworten, personenbezogene Daten zu berichtigen oder zu löschen und diese gegebenenfalls in einem strukturierten Format zur Verfügung zu stellen.
Privacy by Default: Höchste Datenschutzeinstellungen als Standard
Datensparsamkeit und Minimierung der Datenerhebung
Das Prinzip der Datensparsamkeit ist einer der Grundpfeiler des Datenschutzes und ist bereits Bestandteil der Datenschutzgrundsätze aus Art. 5 DSGVO. Es gewinnt bei KI-Systemen, mit denen personenbezogene Daten verarbeitet werden, besondere Bedeutung. Gerade bei der Entwicklung von KI-Modellen ist einer der Erfolgsfaktoren die Sammlung besonders vieler Daten, um die Modelle zu trainieren und zu optimieren. Diesem verständlichen Wunsch steht jedoch der gesetzliche Auftrag zur Datenminimierung entgegen. Es ist deshalb elementar, die Sammlung der Daten rechtlich „sauber“ zu begründen.
In der Praxis bedeutet dies zunächst eine kritische Prüfung: Welche Daten sind für das Training und den Betrieb des KI-Systems wirklich erforderlich? Dabei muss für jedes einzelne Datenelement nachgewiesen werden können, warum es für den angestrebten Zweck erforderlich ist. Diese Prüfung bietet erfahrungsgemäß auch die Chance, Daten, die eben nicht erforderlich sind für den Zweck der KI, die aber irgendwer „nice to have“ fand, erst gar nicht zu sammeln.
Besonders wichtig ist die Unterscheidung zwischen Trainings- und Produktivdaten. Häufig werden für das Training des KI-Models andere oder mehr Daten benötigt als später im produktiven Einsatz. Hier müssen klare Konzepte entwickelt werden, wie mit diesen unterschiedlichen Datensätzen umgegangen wird. Trainingsdaten sollten nach Möglichkeit anonymisiert oder pseudonymisiert werden. Dafür sollte auch der Einsatz synthetischer Daten erwogen werden.
Synthetische Daten werden mit Hilfe von Algorithmen und KI-Methoden generiert, die reale Daten nachahmen. Es handelt sich dabei um simulierte oder künstlich generierte Daten, die so gestaltet sind, dass sie statistische Eigenschaften der echten Daten widerspiegeln, jedoch keine realen, personenbezogenen Informationen enthalten.
Wenn dies nicht möglich ist, muss die Verwendung personenbezogener Daten für das Training besonders gut begründet und dokumentiert werden.
Ein weiterer wichtiger Aspekt ein valides Löschkonzept. Es muss von Anfang an festgelegt werden, wie lange welche Daten gespeichert werden. Dabei sind sowohl die Trainingsdaten als auch die im laufenden Betrieb erhobenen Daten zu berücksichtigen. Dieses Konzept muss entwickelt und technisch umgesetzt werden, bevor das System in Betrieb geht.
Auch die Qualität der Daten spielt eine wichtige Rolle. Unvollständige oder fehlerhafte Daten können nicht nur zu schlechten Ergebnissen führen, sondern stellen auch ein Datenschutzrisiko dar. Es müssen daher Prozesse etabliert werden, die die Datenqualität sicherstellen und regelmäßig überprüfen.
Zweckbindung strikt einhalten und dokumentieren
Die Zweckbindung ist ein weiterer elementarer Grundsatz aus Art. 5 DSGVO. Er gewinnt bei KI-Systemen zusätzliche Brisanz, da diese Systeme häufig in der Lage sind, aus vorhandenen Daten neue Erkenntnisse zu gewinnen, die über den ursprünglichen Erhebungszweck hinausgehen.
In der Praxis bedeutet dies zunächst, dass der Zweck der Datenverarbeitung durch das KI-System bereits vor Beginn der Entwicklung eindeutig und konkret festgelegt werden muss. Vage Formulierungen wie “Verbesserung der Kundenbeziehung” oder “Optimierung der Prozesse” reichen nicht aus. Stattdessen muss präzise beschrieben werden, welche konkreten Ziele mit dem KI-System erreicht werden sollen und warum die geplanten Maßnahmen zur Erreichung dieser Ziele erforderlich sind.
Bei der Verwendung bereits vorhandener Datensätze für das Training von KI-Systemen ist besondere Vorsicht geboten. Es muss genau geprüft werden, ob die geplante Nutzung vom ursprünglichen Erhebungszweck gedeckt ist. Falls nicht, muss entweder eine neue Rechtsgrundlage geschaffen (zum Beispiel durch Einholung einer Einwilligung) oder auf die Nutzung dieser Daten verzichtet werden.
Ein besonders heikler Punkt ist die sogenannte Zweckänderung. Zwar sieht die DSGVO in Art. 6 Abs. 4 die Möglichkeit vor, personenbezogene Daten auch für andere Zwecke zu verarbeiten als die, für die sie ursprünglich erhoben wurden. Dies ist jedoch an so strenge Voraussetzungen geknüpft, dass mir eine Umsetzung in der Praxis kaum realisierbar erscheint. Bei KI-Systemen muss insbesondere geprüft werden, ob die Betroffenen vernünftigerweise mit einer solchen Weiterverarbeitung ihrer Daten rechnen mussten.
Die Dokumentation der Zweckbindung muss lückenlos erfolgen. Dies bedeutet:
- Die Beschreibung des Verarbeitungszwecks im VVT
- Transparente Information der betroffenen Personen in der Datenschutzerklärung
- Sollte Art. 6 Abs. 4 DSGVO tatsächlich zur Rechenschaft der Verarbeitung herhalten: nachvollziehbare Dokumentation etwaiger Zweckänderungen einschließlich der Prüfung der Vereinbarkeit mit dem ursprünglichen Zweck
- Regelmäßige Überprüfung, ob die tatsächliche Nutzung des KI-Systems noch dem dokumentierten Zweck entspricht
Bei der technischen Implementierung sollten Mechanismen vorgesehen werden, die eine zweckfremde Nutzung der Daten verhindern. Dies kann beispielsweise durch getrennte Datenspeicherung, Zugriffskontrollen und Protokollierung erfolgen. Auch das Training des KI-Models sollte so gestaltet werden, dass keine zweckfremden Korrelationen gelernt werden.
Zu guter Letzt: Unbedingt kognitive Verzerrungen vermeiden. Diese Bias genannten in KI eingebauten Vorurteile haben schon so manch gut gemeintes KI-System in argen Misskredit gebracht. Mehr dazu könnt Ihr hier lesen: https://www.linkedin.com/pulse/bias-und-ki-wenn-menschen-maschinen-gemeinsam-die-irre-dirk-wolf-mmyxe/?trackingId=ehmYHAbeWbyfimAtN483fQ%3D%3D
Privacy by Default: Höchste Datenschutzeinstellungen als Standard
Privacy by Default ist neben Privacy by Design der zweite zentrale Grundsatz aus Art. 25 DSGVO. Während Privacy by Design den Datenschutz von Anfang an in die Entwicklung integriert, sorgt Privacy by Default dafür, dass in der fertigen Anwendung die datenschutzfreundlichsten Einstellungen voreingestellt sind.
Bei KI-Systemen bedeutet dies konkret: Die Grundeinstellungen müssen so gewählt sein, dass nur die für den jeweiligen Verarbeitungszweck unbedingt erforderlichen personenbezogenen Daten verarbeitet werden. Dies betrifft:
- Den Umfang der erhobenen Daten
- Die Tiefe der Analyse
- Die Speicherdauer
- Die Zugänglichkeit der Daten
In der Praxis könnte das bei einem KI-gestützten Spenderanalyse-System beispielsweise so aussehen:
- Standardmäßig werden nur grundlegende Spendendaten analysiert, nicht aber zusätzliche Profilinformationen
- Die Verknüpfung mit externen Datenquellen ist standardmäßig deaktiviert
- Analyseergebnisse werden nach einem festgelegten Zeitraum automatisch gelöscht
- Der Zugriff auf detaillierte Analysen ist auf einen minimalen Nutzerkreis beschränkt
Besonders wichtig: Wenn erweiterte Analysefunktionen oder zusätzliche Datenverarbeitungen ermöglicht werden sollen, muss dies aktiv eingeschaltet werden. Dabei ist sicherzustellen, dass:
- Die Aktivierung nur durch autorisierte Personen erfolgen kann
- Die Gründe für die Aktivierung dokumentiert werden
- Die Aktivierung zeitlich begrenzt ist
- Die Auswirkungen der Änderung regelmäßig überprüft werden
Nehmen wir ein KI-System zur Analyse der Spenderkommunikation: In der Standardeinstellung werden E-Mails erst nach 30 Tagen analysiert. Dies gibt Spendenden die Möglichkeit, private Informationen korrigieren oder löschen zu lassen, bevor sie in die Analyse einfließen. Die Textanalyse selbst beschränkt sich voreingestellt auf spendenbezogene Schlüsselwörter. Wenn darüber hinaus auch persönliche Informationen analysiert werden sollen, muss dies aktiv eingeschaltet, begründet und dokumentiert werden.
Bei der Bildverarbeitung, etwa bei Veranstaltungsfotos, zeigt sich Privacy by Default besonders deutlich: Gesichtserkennung ist standardmäßig deaktiviert, Metadaten der Fotos wie Ort, Zeit und Geräteinformationen werden automatisch entfernt. Erst wenn für bestimmte Zwecke eine personenbezogene Auswertung erforderlich ist, kann diese gezielt und zeitlich begrenzt aktiviert werden.
Im Kampagnenmanagement bedeutet Privacy by Default, dass sich die Verarbeitung zunächst auf die aktuelle Kampagne beschränkt. Historische Daten oder kampagnenübergreifende Analysen müssen bewusst einbezogen werden. Das System sammelt in der Grundeinstellung nur die für die konkrete Kampagne notwendigen Daten. Verknüpfungen mit anderen Datensätzen oder die Weitergabe von Analyseergebnissen an andere Systeme sind zunächst blockiert und müssen bei Bedarf einzeln freigeschaltet werden.
Sicherheit durch angemessene technische und organisatorische Maßnahmen (TOMs)
Der Einsatz von KI-Systemen erfordert besondere Sicherheitsmaßnahmen, die über die üblichen TOMs hinausgehen. Dies liegt vor allem daran, dass KI-Systeme nicht nur die aktuell verarbeiteten Daten schützen müssen, sondern auch die Trainingsdaten und die KI-Modelle selbst.
Die Trainingsdaten stellen einen besonders sensiblen Bereich dar. Sie enthalten oft große Mengen historischer Daten, die sorgfältig geschützt werden müssen. In der Praxis hat sich bewährt, Trainingsdaten in einer separaten, besonders geschützten Umgebung zu halten. Der Zugriff wird streng limitiert und jede Nutzung der Daten protokolliert. Werden die Daten nicht mehr für das Training benötigt, müssen sie sicher gelöscht oder zumindest anonymisiert werden, so dass keine Rückschlüsse auf einzelne Personen mehr möglich sind.
Die KI-Modelle selbst bedürfen ebenfalls besonderer Schutzmaßnahmen. Ein kompromittiertes Modell könnte nicht nur falsche Entscheidungen treffen, sondern auch sensible Informationen aus den Trainingsdaten preisgeben. Daher muss der Zugriff auf die Modelle streng kontrolliert werden. Updates oder Änderungen am Modell dürfen nur nach einem definierten Freigabeprozess erfolgen. Regelmäßige Sicherheitstests sollten prüfen, ob das Modell manipuliert wurde oder unerwartetes Verhalten zeigt.
Bei der Übertragung von Analyseergebnissen ist besondere Vorsicht geboten. Die Ergebnisse können durch Verknüpfung verschiedener Teilinformationen neue, möglicherweise sensitive Erkenntnisse offenbaren. Daher sollten Analyseergebnisse nur verschlüsselt übertragen und nur an zuvor definierte Empfänger weitergegeben werden. Die Empfänger müssen geschult sein, wie sie mit den Ergebnissen datenschutzkonform umgehen.
Ein oft unterschätzter Aspekt ist die Protokollierung. Bei KI-Systemen muss nicht nur der Zugriff auf Daten protokolliert werden, sondern auch, welche Modelle wann für welche Analysen verwendet wurden. Diese Protokolle sind wichtig für die Nachvollziehbarkeit von Entscheidungen und für die Erfüllung der Rechenschaftspflicht aus Art. 5 Abs. 2 DSGVO. Sie müssen so gestaltet sein, dass sie im Falle einer Datenschutzanfrage oder -prüfung aussagekräftige Informationen liefern können.
Regelmäßige Überprüfung und Dokumentation
KI-Systeme sind keine statischen Anwendungen – sie entwickeln sich durch neue Trainingsdaten und Anpassungen kontinuierlich weiter. Dies erfordert systematische Überprüfungen und eine lückenlose Dokumentation aller Änderungen.
Die Qualitätskontrolle der Systemergebnisse ist dabei ein zentraler Aspekt. Während zu Beginn die Ergebnisse meist intensiv geprüft werden, darf diese Kontrolle im Laufe der Zeit nicht vernachlässigt werden. Ein KI-System kann sich durch neue Daten unmerklich verändern, etwa wenn sich das Nutzerverhalten wandelt oder neue Arten von Fällen auftreten. Regelmäßige Stichproben und der Vergleich mit menschlichen Einschätzungen helfen, solche schleichenden Veränderungen frühzeitig zu erkennen.
Die Wirksamkeit der Datenschutzmaßnahmen muss ebenfalls kontinuierlich überprüft werden. Was bei der Einführung des Systems angemessen war, kann durch technische Entwicklungen oder neue Bedrohungsszenarien überholt sein. Beispielsweise könnten neue Angriffsmethoden entwickelt worden sein, die es ermöglichen, aus anonymisierten Daten doch wieder Rückschlüsse auf Personen zu ziehen. Oder es entstehen neue Möglichkeiten der Datenverschlüsselung, die implementiert werden sollten.
Besonders wichtig ist die regelmäßige Risikobewertung. Neue Funktionen oder Datenquellen können zusätzliche Risiken für die Rechte und Freiheiten der betroffenen Personen mit sich bringen. Wenn etwa ein ursprünglich für die Spenderanalyse entwickeltes System um Funktionen zur Verhaltensvorhersage erweitert wird, muss diese Erweiterung sorgfältig auf ihre Datenschutzauswirkungen geprüft werden.
Die Datenqualität ist ein weiterer kritischer Faktor. Im Laufe der Zeit können sich Datenformate ändern, neue Datenfelder hinzukommen oder alte wegfallen. Auch die Bedeutung bestimmter Datenwerte kann sich wandeln. All diese Veränderungen müssen erkannt und ihre Auswirkungen auf das KI-System bewertet werden.
Nicht zuletzt müssen auch die ursprünglichen Annahmen regelmäßig hinterfragt werden. Stimmen die bei der Entwicklung getroffenen Grundannahmen noch? Sind die gelernten Muster noch relevant? Hat sich der Einsatzkontext des Systems wesentlich verändert? Diese Fragen müssen regelmäßig gestellt und die Antworten dokumentiert werden.
Die Dokumentation all dieser Überprüfungen ist dabei nicht nur eine formale Pflicht, sondern ein wichtiges Werkzeug für die kontinuierliche Verbesserung des Systems. Sie hilft, Entwicklungen über die Zeit zu erkennen und fundierte Entscheidungen über notwendige Anpassungen zu treffen.
All diese Maßnahmen werden NICHT vom DSB vorgenommen, sondern vom Verantwortlichen, der die Aufgaben an fachkundige interne oder externe Expert*innen delegiert.
Intervenierbarkeit: Möglichkeit für manuelle Eingriffe und Korrekturen
Auch das beste KI-System kann Fehler machen oder in unerwartete Situationen geraten. Daher muss jederzeit die Möglichkeit bestehen, manuell in die Prozesse einzugreifen. Dies ist nicht nur eine technische Notwendigkeit, sondern auch eine rechtliche Anforderung, insbesondere im Kontext von Art. 22 DSGVO.
Die Intervenierbarkeit muss auf verschiedenen Ebenen gewährleistet sein. Zunächst benötigen die Fachabteilungen die Möglichkeit, einzelne Entscheidungen des Systems zu überprüfen und gegebenenfalls zu korrigieren. Ein Beispiel aus dem Fundraising: Wenn das KI-System einem langjährigen Großspender fälschlicherweise nur noch Kleinspendenprojekte vorschlägt, muss dies umgehend korrigiert werden können. Dabei reicht es nicht, nur die konkrete Empfehlung anzupassen – es muss auch analysiert werden, warum das System zu dieser Fehleinschätzung kam.
Systemadministratoren benötigen weitergehende Eingriffsmöglichkeiten. Sie müssen in der Lage sein, bestimmte Funktionen des Systems zeitweise zu deaktivieren oder Parameter anzupassen. Wenn etwa festgestellt wird, dass das System bei bestimmten Personengruppen systematisch falsche Entscheidungen trifft, muss die entsprechende Analysefunktion ausgesetzt werden können, bis die Ursache gefunden und behoben ist.
Besonders wichtig ist die Möglichkeit zum Eingriff bei der Verarbeitung personenbezogener Daten. Betroffene Personen müssen ihre Rechte effektiv ausüben können – von der Korrektur falscher Daten bis hin zum Widerspruch gegen bestimmte Analysen. Das System muss so gestaltet sein, dass solche Eingriffe technisch möglich sind und ihre Auswirkungen nachvollzogen werden können.
Ein oft übersehener Aspekt ist die “Notbremse”: In kritischen Situationen muss das System schnell und sicher gestoppt werden können. Dies gilt besonders dann, wenn Fehlfunktionen erkannt werden oder der Verdacht besteht, dass das System kompromittiert wurde. Bitte unbedingt beachten: die Prozesse für solche Notfälle müssen vorab definiert und regelmäßig getestet werden.
Die Intervenierbarkeit muss auch dokumentiert werden. Jeder manuelle Eingriff sollte protokolliert werden: Wer hat wann welche Änderung vorgenommen und warum? Diese Dokumentation ist wichtig für die Nachvollziehbarkeit und hilft, das System kontinuierlich zu verbessern.
Transparenz für Betroffene gewährleisten
Die Transparenzpflicht ist ebenfalls, wie schon die Zweckbindung und die Rechenschaftspflicht einer der zentralen Grundsätze der DSGVO (Art. 5 Abs. 1 lit. a, Art. 12 ff. DSGVO). Bei KI-Systemen stellt sie eine besondere Herausforderung dar, weil die Verarbeitung personenbezogener Daten hier oft besonders komplex ist. Die betroffenen Personen müssen dennoch klar und verständlich über die Verarbeitung ihrer Daten informiert werden.
Das bedeutet zunächst, dass die Datenschutzinformationen in präziser, transparenter, verständlicher und leicht zugänglicher Form in einer klaren und einfachen Sprache zur Verfügung gestellt werden müssen. Bei KI-Systemen muss dabei insbesondere erklärt werden:
- Dass ein KI-System zum Einsatz kommt
- Welche Arten von Daten das System verarbeitet
- Zu welchem Zweck die Verarbeitung erfolgt
- Welche Auswirkungen die KI-gestützte Verarbeitung für die Betroffenen haben kann
- Wie die Betroffenen ihre Rechte wahrnehmen können
Besonders wichtig ist die Information über automatisierte Entscheidungsfindungen. Falls das KI-System Entscheidungen trifft, die rechtliche Wirkung gegenüber den betroffenen Personen entfalten oder sie in ähnlicher Weise erheblich beeinträchtigen, müssen die Betroffenen aussagekräftige Informationen über die involvierte Logik sowie die Tragweite und angestrebten Auswirkungen erhalten.
Allerdings bedeutet Transparenz nicht, dass der komplette Algorithmus offengelegt werden muss. Es reicht aus, den Betroffenen die grundlegende Funktionsweise und die wesentlichen Kriterien der Entscheidungsfindung zu erläutern. Dies kann beispielsweise durch vereinfachte Visualisierungen oder Beispiele erfolgen.
Was aber nicht bedeutet, dass dem Entwicklungsteam die tiefere Kenntnis der Funktionsweise des KI-Systems egal sein kann. Wie sie diese Kenntnis erlangen kann, erkläre ich im Artikel „Fünf häufige Missverständnisse über KI und Datenschutz – KI-Lernreise Woche 3, Beitrag 2“ und hier unter „Exkurs“ bei Punkt 3: https://www.linkedin.com/pulse/f%25C3%25BCnf-h%25C3%25A4ufige-missverst%25C3%25A4ndnisse-%25C3%25BCber-ki-und-datenschutz-dirk-wolf-gbcke/?trackingId=adX9j9Jdjoxoc1ziI0u%2BpA%3D%3D
Ein paar Praxishinweise zur Umsetzung der Transparenz
Die praktische Umsetzung der Transparenzanforderungen kann und sollte mehrschichtig erfolgen. Auf der ersten Ebene – etwa in der Datenschutzerklärung auf der Website – werden die grundlegenden Informationen in allgemein verständlicher Sprache bereitgestellt.
Dazu ein allgemeiner Hinweis: Datenschutzerklärungen auf der Website werden oft ausschließlich für den Betrieb des Internetauftritts geschrieben. Sie sind aber auch ein idealer Ort, um Datenschutzhinweise für alle anderen Verarbeitungen personenbezogener Daten zu geben. Außerdem erleichtert das die Wartung der Datenschutzinformationen erheblich, da nicht mehr gesucht werden muss, wo welche Informationen gegeben wurden.
Für interessierte Betroffene sollten detailliertere Informationen in einer zweiten Ebene zur Verfügung stehen.
Art. 12 Abs. 1 DSGVO verpflichtet uns „der betroffenen Person alle Informationen gemäß den Art. 13 und 14 und alle Mitteilungen gemäß den Artikeln 15 bis 22 und Artikel 34, die sich auf die Verarbeitung beziehen, in präziser, transparenter, verständlicher und leicht zugänglicher Form in einer klaren und einfachen Sprache zu übermitteln“. Puh… Das ist nicht einfach, besonders, wenn es um so komplexe Systeme wir KI geht.
Das ist nicht einfach, aber auch nicht unmöglich. Zu empfehlen sind beispielsweise interaktive Elemente: Wenn das KI-System eine Empfehlung ausspricht oder eine Entscheidung trifft, könnte direkt an dieser Stelle einen Link platziert werden, der erklärt, wie diese Empfehlung oder Entscheidung zustande gekommen ist. Formulierungen wie “Warum sehe ich diese Empfehlung?” oder “Wie wurde diese Entscheidung getroffen?” laden zur weiteren Information ein. Durch die Form des Links können Betroffene selbst entscheiden, ob sie eine tiefergehende Erklärung wünschen.
Bei der Gestaltung der Informationen ist zu berücksichtigen, dass viele Betroffene keine technischen Vorkenntnisse haben. Statt von “Machine Learning Algorithmen” oder “neuronalen Netzen” zu sprechen, sollten besser Formulierungen wie “automatische Analyse” oder “computergestützte Auswertung” verwendet werden. Beispiele aus dem Alltag der Betroffenen können helfen, komplexe Zusammenhänge verständlich zu machen.
Besonders wichtig ist auch die Information darüber, wie Betroffene aktiv werden können. Dies umfasst nicht nur die klassischen Betroffenenrechte wie Auskunft oder Löschung, sondern auch spezifische Handlungsmöglichkeiten im Zusammenhang mit der KI. Etwa die Option, bestimmte Analysen abzulehnen oder Korrekturen an den verwendeten Daten vorzunehmen.
Die Wirksamkeit der Transparenzmaßnahmen sollte regelmäßig überprüft werden, beispielsweise durch Nutzerfeedback oder Tests mit verschiedenen Zielgruppen. Auf dieser Basis können die Informationen kontinuierlich verbessert und an die Bedürfnisse der Betroffenen angepasst werden.
Hier kommen noch einige Muster-Texte für die Information gemäß Art. 13 und 14 DSGVO:
Beispiel 1: Zur Analyse von Spendenmuster
“Wir nutzen moderne Analysemethoden, um Ihre Spende bestmöglich einzusetzen. Dabei werden Ihre bisherigen Spenden anonym ausgewertet, um zum Beispiel zu erkennen, welche Projekte für Sie besonders interessant sein könnten.”
Beispiel 2: Zur Verwendung von KI in der Fallbearbeitung
“Um Hilfsanfragen schneller bearbeiten zu können, nutzen wir ein computergestütztes System. Dieses macht Vorschläge für passende Unterstützungsangebote. Die finale Entscheidung trifft aber immer ein Mensch aus unserem Team.”
Beispiel 3: Zur Kommunikation über den Einsatz von KI-Systemen im medizinischen Bereich bei der Analyse von Röntgenbildern
“Zur Unterstützung unserer Ärztinnen und Ärzte setzen wir ein computergestütztes Analysesystem ein. Dieses hilft dabei, auffällige Bereiche im Röntgenbild zu markieren. Die medizinische Beurteilung erfolgt ausschließlich durch unsere Fachkräfte.”
Art. 22 Abs. 1 DSGVO schützt Betroffene vor automatisierten Entscheidungen, die rechtliche oder ähnlich schwerwiegende Auswirkungen haben können. Die Beispiele 2 und 3 zeigen, wie dieser Schutz in der Praxis aussehen kann: Das KI-System macht zwar Vorschläge, die finale Entscheidung liegt aber immer bei einem Menschen – sei es beim Mitarbeitenden im Hilfsprojekt oder bei der medizinischen Fachkraft.
Betroffenenrechte technisch und organisatorisch sicherstellen
Die DSGVO gewährt den Betroffenen in den Artikeln 15 bis 22 umfassende Rechte. Die technische und organisatorische Umsetzung dieser Rechte stellt Verantwortliche bei KI-Systemen vor eine der größten Herausforderungen überhaupt – sie kann sogar über Erfolg oder Misserfolg des gesamten KI-Projekts entscheiden. Deshalb ist es wichtig, sich dieser Herausforderung von Anfang an zu stellen. Wenn über die Umsetzung der Rechte der Betroffenen erst am Ende gesprochen wird, kann bereits sehr viel Geld „verbrannt“ sein.
In der Praxis bedeutet dies zunächst, dass das KI-System so konzipiert sein muss, dass es Auskunftsanfragen effizient beantworten kann. Dies umfasst nicht nur die Fähigkeit, alle über eine Person gespeicherten Daten zu finden, sondern auch nachvollziehbar darzustellen, wie diese Daten in das System gekommen sind und wie sie von dem System verwendet werden. Besonders wichtig ist dabei die Dokumentation, welche Daten in welcher Form in das Training des Systems eingeflossen sind.
Das Recht auf Berichtigung erfordert technische Mechanismen, die es ermöglichen, fehlerhafte Daten nicht nur zu korrigieren, sondern auch den Einfluss dieser Daten auf bereits getroffene Entscheidungen nachzuvollziehen. Gegebenenfalls müssen Analysen oder Entscheidungen neu durchgeführt werden.
Besonders komplex ist die Umsetzung des Rechts auf Löschung (“Recht auf Vergessenwerden”). Bei KI-Systemen muss sichergestellt werden, dass die zu löschenden Daten nicht nur aus den aktiven Systemen entfernt werden, sondern auch aus Backup-Systemen und – soweit technisch möglich – aus den Trainingsmodellen. Die Herausforderungen im Einzelnen betrachtet:
Art. 15 DSGVO „Recht auf Auskunft“
Die erste große Herausforderung für die Auskunftspflicht gemäß Art. 15 DSGVO ist, dass bei KI-Systemen nicht nur alle über eine Person gespeicherten Daten gefunden werden müssen. Es muss auch transparent gemacht werden, wie diese Daten vom System verwendet werden. Eine besondere Schwierigkeit dabei: Es muss nachvollziehbar dokumentiert werden, welche Daten in welcher Form in das Training des Systems eingeflossen sind und wie sie die Entscheidungen des Systems beeinflussen. In der Praxis erfordert dies ein durchdachtes Datenmanagement-System, das folgende Aspekte abdeckt:
- Eine klare Trennung zwischen Trainings- und Produktivdaten
- Eine lückenlose Protokollierung der Datenverwendung
- Mechanismen zur Nachverfolgung von Datenflüssen im System
- Eine verständliche Aufbereitung der technischen Zusammenhänge für die Auskunftserteilung
Die zweite große Herausforderung bei der Auskunftspflicht ist die Information über die Logik des KI-Systems. Art. 15 Abs. 1 lit. h DSGVO verlangt bei automatisierten Entscheidungen “aussagekräftige Informationen über die involvierte Logik”. Dies bedeutet nicht, dass der komplette Algorithmus offengelegt werden muss – was bei modernen KI-Systemen ohnehin kaum möglich wäre. Erforderlich ist vielmehr eine verständliche Erklärung der grundlegenden Funktionsweise: Welche Faktoren werden für Entscheidungen herangezogen? Wie werden sie gewichtet? Welche Rolle spielen historische Daten?
Umgesetzt werden könnte das durch verschiedene Ansätze:
Visualisierungen der wichtigsten Entscheidungsfaktoren
Für die Visualisierung der Entscheidungsfaktoren könnten verschiedene Darstellungsformen gewählt werden. Ein guter Ansatz ist das “Entscheidungsgewicht-Diagramm”: Es zeigt für eine konkrete Entscheidung die relative Bedeutung der verschiedenen Faktoren, etwa in Form eines horizontalen Balkendiagramms. Beispielsweise könnte bei einem KI-System zur Spendenanalyse dargestellt werden, dass die “Spendenhäufigkeit” zu 40%, die “Spendenhöhe” zu 30%, das “Engagement bei speziellen Kampagnen” zu 20% und die “Reaktion auf Newsletter” zu 10% zur Entscheidung beitragen.
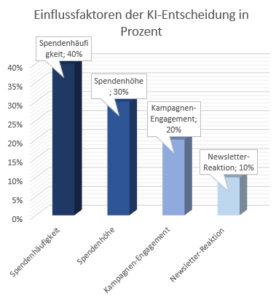
Diese Grafik zeigt, wie stark verschiedene Faktoren die Empfehlungen unseres Systems beeinflussen. Die Spendenhäufigkeit hat dabei den größten Einfluss, gefolgt von der Spendenhöhe und dem Kampagnen-Engagement. Der Newsletter-Response hat den geringsten Einfluss.
Konkrete Beispiele für typische Entscheidungswege
Die abstrakten Entscheidungsprozesse eines KI-Systems lassen sich am besten durch konkrete Beispiele veranschaulichen. Bei meinem Spenden-Analyse-System von oben könnte ein typischer Entscheidungsweg so aussehen: “Eine Person spendet seit drei Jahren regelmäßig (Spendenhäufigkeit) kleinere Beträge (Spendenhöhe) für Bildungsprojekte, hat sich bei der letzten Bildungskampagne besonders engagiert (Kampagnen-Engagement) und öffnet regelmäßig unsere Newsletter (Newsletter-Response). Auf dieser Basis schlägt das System vor, diese Person gezielt über neue Bildungsprojekte zu informieren und für das Bildungs-Patenprogramm in Ruanda anzusprechen.”
Solche Beispiele helfen den Betroffenen zu verstehen, wie ihre persönlichen Daten in konkrete Entscheidungen einfließen. Wichtig ist dabei, dass die Beispiele aus dem tatsächlichen Einsatzbereich des Systems stammen und alle relevanten Entscheidungsfaktoren berücksichtigen.
Verständliche Erklärungen für verschiedene Zielgruppen (technisch/nicht-technisch)
Zielgruppengerechte Ansprache kennen wir aus dem Fundraising/Marketing schon seit Langem. Seit dem 23.05.2018 müssen wir nun auch eine zielgruppengerechte „Information der Betroffenen“ vornehmen.
Die Erklärung der KI-Funktionsweise muss also auf die jeweilige Zielgruppe zugeschnitten sein. Die Information nach Art. 13 und 14 DSGVO kann also ganz unterschiedlich ausfallen.
Für technisch interessierte Betroffene könnte die Erklärung etwa lauten:
“Unser System analysiert Ihre Spendenhistorie mithilfe eines maschinellen Lernverfahrens. Es erkennt Muster in Ihrem Spendenverhalten und gleicht diese mit ähnlichen Spendenprofilen ab, um passende Projektvorschläge zu entwickeln.”
Für Betroffene ohne technischen Hintergrund eignet sich eher eine alltagsnähere Formulierung:
“Stellen Sie sich unser System wie einen aufmerksamen Gesprächspartner vor. Es merkt sich, welche Projekte Sie in der Vergangenheit unterstützt haben und wie Sie das getan haben. Auf dieser Basis kann es einschätzen, welche neuen Projekte Sie interessieren könnten.”
Für die Fachabteilungen wiederum braucht es detailliertere Informationen:
“Das System nutzt einen überwachten Lernansatz, der auf historischen Spendendaten trainiert wurde. Es berücksichtigt dabei zeitliche Muster, Projekt-Präferenzen und Interaktionsverhalten, um die Wahrscheinlichkeit für das Interesse an bestimmten Projekten vorherzusagen.”
Dokumentation der Grundannahmen und Trainingsprinzipien des Systems
Die technische Dokumentation des KI-Systems muss sowohl die Grundannahmen als auch die Trainingsprinzipien nachvollziehbar festhalten. Dies ist nicht nur für die Erfüllung der Rechenschaftspflicht nach Art. 5 Abs. 2 DSGVO wichtig, sondern auch für die langfristige Wartung und Weiterentwicklung des Systems.
Auswahl der Trainingsdaten
Bei der Auswahl der Trainingsdaten müssen die grundlegenden Annahmen klar dokumentiert werden. Wurde beispielsweise angenommen, dass historische Spendendaten auch für zukünftiges Spendenverhalten aussagekräftig sind? Oder dass das Verhalten von Spendenden in einer Region auf andere Regionen übertragbar ist? Wurde angenommen, dass Spendende, die bisher nur zu Weihnachten gespendet haben, auch für Katastrophenhilfe-Aufrufe empfänglich sind? Oder dass Personen, die bisher nur Einzelspenden geleistet haben, auch für eine Fördermitgliedschaft gewonnen werden können? Solche Grundannahmen beeinflussen maßgeblich die späteren Systementscheidungen und müssen daher kritisch hinterfragt und dokumentiert werden.
Kriterien für die Auswahl und Aufbereitung der Trainingsdaten
Die Kriterien für die Auswahl und Aufbereitung der Trainingsdaten sind ebenfalls entscheidend. Wurde ein bestimmter Zeitraum gewählt? Wurden bestimmte Datensätze ausgeschlossen und wenn ja, warum? Wie wurden fehlende oder fehlerhafte Daten behandelt? Die Dokumentation dieser Entscheidungen ist wichtig, um später nachvollziehen zu können, auf welcher Basis das System arbeitet.
Dokumentation der Maßnahmen gegen Verzerrungen (Bias)
Besonders wichtig ist die Dokumentation der Maßnahmen gegen Verzerrungen (Bias). Wurde beispielsweise überprüft, ob bestimmte Personengruppen in den Trainingsdaten über- oder unterrepräsentiert sind? Wurden Korrekturmaßnahmen ergriffen, etwa durch gezielte Gewichtung der Daten oder den Einsatz synthetischer Datensätze? Die Vermeidung von Diskriminierung ist nicht nur ethisch geboten, sondern auch rechtlich erforderlich.
Qualitätssicherung der Trainingsergebnisse
Die Qualitätssicherung der Trainingsergebnisse muss nachvollziehbar dokumentiert werden. Welche Metriken wurden zur Bewertung der Modellqualität herangezogen? Wie wurde das Modell mit Testdaten validiert? Wurden Vergleiche mit menschlichen Entscheidungen durchgeführt? Diese Qualitätskontrollen sind entscheidend für die Zuverlässigkeit des Systems.
Dokumentation der Grenz- und Schwellenwerte
Schließlich müssen auch die festgelegten Grenz- und Schwellenwerte dokumentiert werden. Ab welchem Konfidenzwert trifft das System eine bestimmte Entscheidung? Welche Mindestanforderungen müssen erfüllt sein, damit eine Empfehlung ausgesprochen wird? Diese Werte beeinflussen direkt die Funktionsweise des Systems und müssen daher sorgfältig begründet und dokumentiert werden.
Ende des ersten Teils.
Dieser erste Teil hat die grundlegenden Konzepte und deren praktische Umsetzung behandelt. Dabei wurde deutlich, wie wichtig es ist, Datenschutz von Anfang an in KI-Systeme zu integrieren. Im zweiten Teil werde ich auf die konkreten technischen Implementierungsmöglichkeiten eingehen. Dabei werden wir uns mit modernen Schutzkonzepten wie Differential Privacy und Federated Learning beschäftigen, aber auch mit organisatorischen Best Practices und Zukunftsperspektiven.
Was haltet Ihr von der Idee, die Website-Datenschutzerklärung als zentralen Informations-Hub für alle Datenverarbeitungen zu nutzen?
Wie geht Ihr mit der Spannung zwischen dem Wunsch nach möglichst vielen Trainingsdaten und dem Grundsatz der Datensparsamkeit um?
Habt Ihr schon Erfahrungen mit der Dokumentation von KI-Systemen gemacht? Welche Ansätze haben sich bei Euch bewährt?
Welche der vorgestellten Konzepte erscheinen Euch besonders praxistauglich – welche seht Ihr kritisch?
Ich freue mich auf Eure Kommentare und Erfahrungsberichte!”
#KIundDatenschutz #DSGVO #KünstlicheIntelligenz #Datenschutzbeauftragter #PrivacyByDesign